
tomorrow.cyz@gmail.com
1. http协议概览
先通过两个协议包认识下http协议
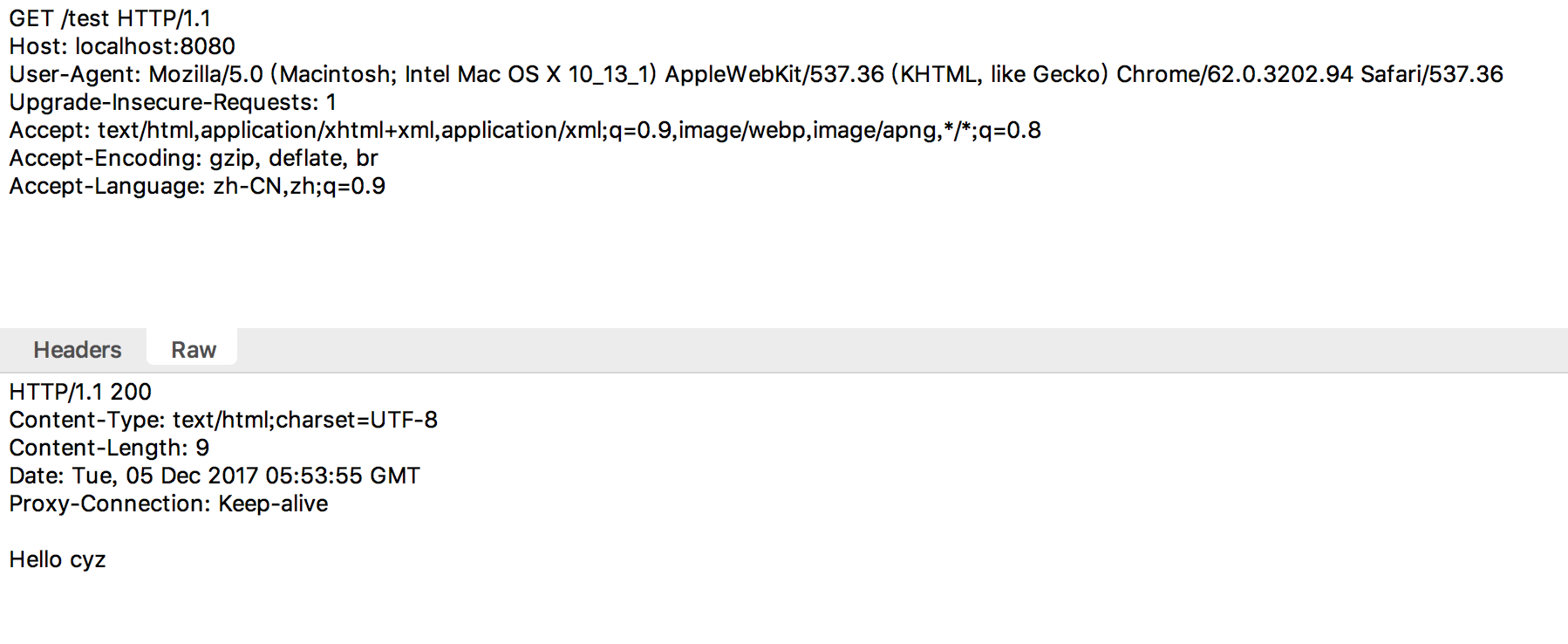
图1是一个简单的http get请求,UA(浏览器或者客户端)想要获取
某个资源,就发送一个请求,在请求参数里面包含了资源的位置,
服务器端收到请求,将对应的响应数据发送给浏览器或者客户端。
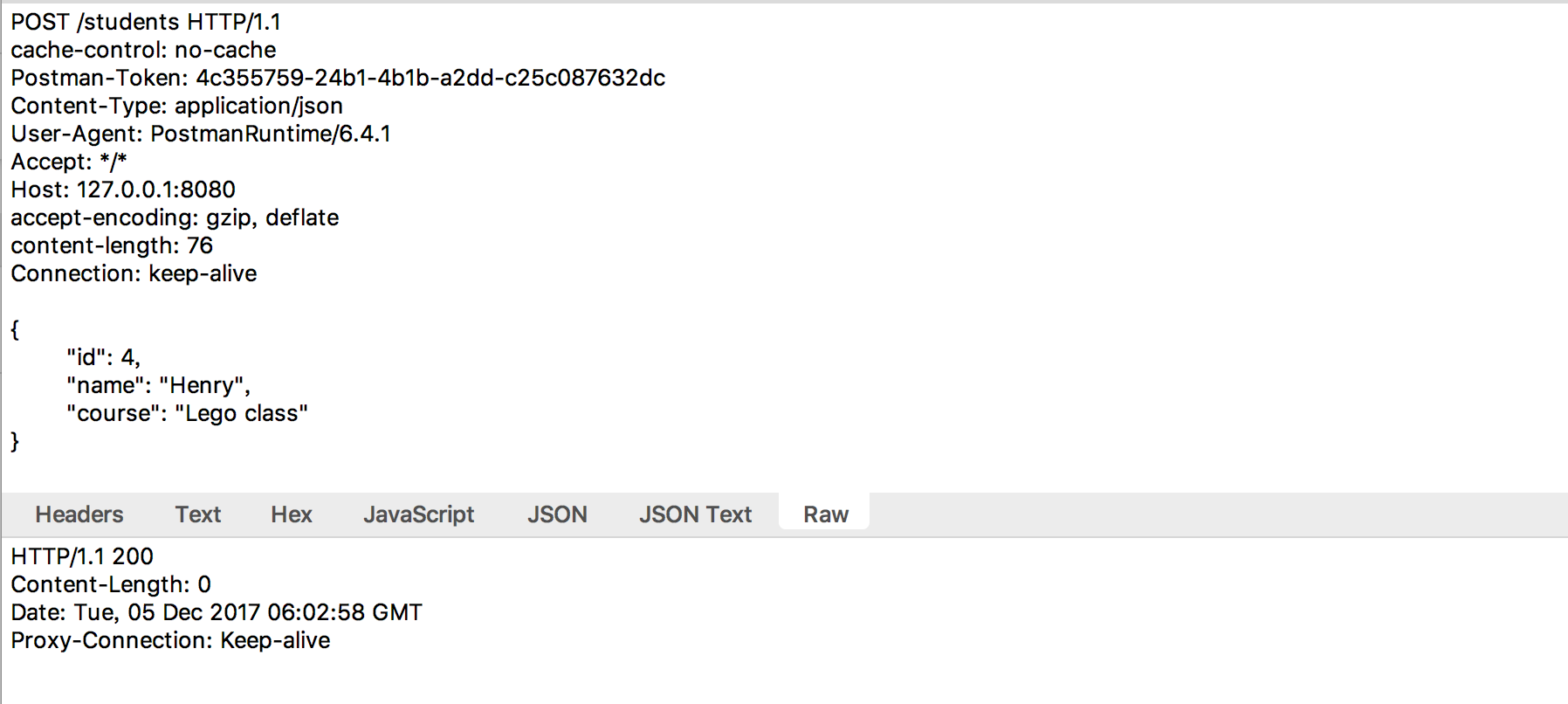
图2是一个http post请求,可以用来提交信息给服务器,服务器收到
了数据,处理数据(比如持久化),然后将结果返回给UA。
-
http协议是应用层协议,通常运行在tcp协议之上
http协议需要保证顺序的可靠传输
-
http协议被广泛应用于传输各种类型的数据
-
http协议是一个请求–响应模型
-
http协议是无状态的
http协议是无状态的,它没有事务处理能力,一个请求 响应的过程就完成全部的生命周期。当服务器端希望在两个或多个请 求之间实现状态的时候,要自己来处理(比如可以使用cookie或者url 的query携带状态信息).
在移动应用里面,http协议是前端和后端的桥梁。
- 明文传输
http协议本身,包括头和体部是通过明文传输的。引入 https可以对传输的协议数据进行加密。
http2.0引入了二进制分帧层,分帧层使用二进制编码,而 不是明文。
2. http和tcp的关系
http是应用层协议,tcp是传输层协议,http通常运行与tcp协议之上。
如图3是http端到端的数据流,可以看到http协议数据放在tcp协议体部传递。

图4是wireshark抓到的一个服务器端http请求的tcp流,可以看到UA首先进行tcp三次握手(连接),成功以后 UA发送http请求数据,服务器端收到Http请求,利用tcp发送响应数据,然后UA断开tcp连接。

在http协议的客户端具体实现里面,一般会调用socket来连接服务器,发送和接受数据,所以存在三个超时可能( 连接超时,发送超时,接收超时)。
考虑到tcp慢启动的特性,tcp三次握手给http带来了延迟影响不小,HTTP协议一直致力于减少这个影响。先是在HTTP1.1 引入了永久连接(也就是很多APP网络优化里面提到的http长连接),并引入了pipeline的概念,但是pipeline因为部署困 难,浏览器服务器都支持不好,应用不广。HTTP2.0则推出了Multiplexing的概念,比pipeline更近一步(pipeline要求 服务器按照收到请求的顺序返回响应,Multiplexing可以乱序)。
在使用域名而不是ip的情况,还需要一次dns解析(getHostByName)。
和tcp连接相关的一系列优化手段包括http长连接,域名合并,httpdns。
这里还有一个细节就是要控制请求头长度,尽量不要让它超过1500(一个MTU的长度),超过的话,一个请求头就会分成两个 ip包传输。
3. 请求与响应
3.1 请求
http请求从UA向server发起,包含方法,资源标识,请求头和请求体部,请求体部是可选的。
Request = Request-Line
*(( general-header
| request-header
| entity-header ) CRLF)
CRLF
[ message-body ]
请求头部和体部之间的分隔是两个CRLF(\r\n)
3.1.1 请求方法
请求方法包括GET,POST,HEAD,PUT,DELETE,TRACE,CONNECT,OPTIONS,这些方法都有一定的语法意义,但是 具体的行为更多地依赖于服务器的实现。
现在主流的API是RESTFul风格的,针对CRUD,分别对应post,get,put和delete方法。
3.1.2 内容协商
同一个资源可能提供多种形式的版本,比如现在的APP,早期的接口都是JSON格式了,后期可能实现了Protocolbuf, 就会有两种格式的版本,对低版本的APP的请求提供JSON格式,对高版本的提供Protocolbuf格式的。这个就是在客户 端和服务端协商的结果。
内容协商的原理,通常是UA告诉服务端自己的偏好,服务端根据UA的偏好选择合适的版本给UA。
常见的内容协商相关的请求/响应头部有:
请求头字段 说明 响应头字段
Accept 告知服务器发送何种媒体类型 Content-Type
Accept-Language 告知服务器发送何种语言 Content-Language
Accept-Charset 告知服务器发送何种字符集 Content-Type
Accept-Encoding 告知服务器采用何种压缩方式 Content-Encoding
如下是内容协商的一个请求头的例子
Accept:*/*
Accept-Encoding:gzip,deflate,sdch
Accept-Language:zh-CN,en-US;q=0.8,en;q=0.6
对应的响应头部
Content-Type: text/javascript
Content-Encoding: gzip
Content-Language: en-US
另外,User-Agent这个请求头部在移动互联网里被广泛使用,扩展了越来越多的信息,比如屏幕尺寸,分辨率,厂家信 息,os版本等,服务器端会根据User-Agent产生不同的响应,这也可以看做内容协商的另一种形式。
考虑下这个情况,如果服务端提供了JSON和ProtocolBuf两个版本给APP,低版本的用JSON,高版本用PB,通常为了提高 服务端的负载,会在后端集群前面加代理,比如vanish,这个时候vanish要收到一个请求,怎么来确定缓存的策略呢? 通用的http代理服务器也有同样的问题。
这个时候在响应头部引入了一个Vary头部。 假设我们是通过Accept头部进行JSON和PB的协商的,那么后端可以加
Vary:Accept
用来告诉缓存服务器,根据不同的Accept头部,缓存和筛选相应的响应版本。
3.2 响应
http的响应由状态行,响应头部和响应体部组成
Multiplexing
Response = Status-Line
*(( general-header
| response-header
| entity-header ) CRLF)
CRLF
[ message-body ]
响应行由版本,状态码和描述组成。
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
3.2.1 状态码
http将状态码分为5类:
- 1xx: Informational - Request received, continuing process
- 2xx: Success - The action was successfully received,
understood, and accepted
- 3xx: Redirection - Further action must be taken in order to
complete the request
- 4xx: Client Error - The request contains bad syntax or cannot
be fulfilled
- 5xx: Server Error - The server failed to fulfill an apparently
valid request
1xx的状态码现在已经用的很少。用的比较多的分别是
| "200" OK
| "301" Moved Permanently
| "302" Found
| "304" Not Modified
| "307" Temporary Redirect
| "400" Bad Request
| "401" Unauthorized
| "403" Forbidden
| "404" Not Found
| "407" Proxy Authentication Required
| "500" Internal Server Error
| "502" Bad Gateway
| "503" Service Unavailable
| "504" Gateway Time-out
3.2.2 压缩和传输编码
通常指的http压缩是内容编码的一种,通过gzip/compress等方式,将http体部数据压缩后传输, 可以达到减少数据传输的目的。
http压缩可以通过内容协商的方式进行协商(Accept-Encoding/Content-Encoding)。
纯文本有很高的压缩率。所以一般对html/css/javascipt,会全站设置使用gzip。
php有个开源项目minify,就是把一个页面的css和js合并到一个文件,然后再进行压缩。
相对于内容编码,传输编码是另外一个概念。传输编码不是为了压缩某一个资源,而是为了保证 资源被“安全传输”。常见的传输编码就是chunked。
早期http1.0是通过服务器端关闭tcp连接来确定http体部结束的,http1.1引入了content-length 头部,当收到体部数据达到content-length长度的时候,就可以判定体部结束了。但是有些情况下, 服务器开启传输的时候,不好确定数据的长度,比如某些情况下的流式数据。这个时候就引入了chunk, 将数据分成一块块,每块包含块信息(块长度,是不是最后一块等),如果最后一块,收到了那块长度 的数据,体部结束。这些块信息包含在体部里面,而不是头部。
chunk一个很经典的应用,比如一个动态页面,包含头部,边栏,尾部,正文,每个区域可能都要根据数 据库动态生成,响应时间会比较长,这个时候一种方法是ajax,后端提供多个接口,分别请求,再渲染, 还有一种方式,可以分成多个chunk来返回,比ajax还省掉了http请求流程。
3.2.3 断点续传
断点续传在文件下载的时候用得非常普遍。
http协议通过请求的range头部,if-range头部和响应的content-range头部,206的状态码实现了这个功能。
比如,假设收到了某一个资源的前500字节的内容,响应的Last-Modified为Wed,6,Dec 2017 17:48:02 GMT
在请求里面加入头部
range:bytes 501-
if-range:Wed,6,Dec 2017 17:48:02 GMT
服务器如果支持断点续传,且资源没有改变,会返回HTTP 206 Partial Content,带content-range头部
content-range:bytes 501-1024/1024
如果资源在Last-Modified之后又改动,则返回200,从头开始接收。
另外,响应有个Accept-Range头部,服务端可以用来向UA告知自己的分部请求能力。
4. 缓存
缓存在web或者app的网络优化中都占据比较重要的位置,其实目标很简单,UA在从服务端获取一次资源 之后,希望如果服务端不改动,UA都可以从本地获取,如果服务端有改动,UA就从服务端获取。有的APP 还有一个目标,在network不可用的情况下,使用缓存数据。
为了实现这个目标,http请求头部和响应头部引入了一些特殊的头部。缓存的规则非常复杂,http协议专门 有一章(section14.9 Cache-Control)介绍。这里只介绍常用的。
4.1 ETAG和Last-Modified
为了帮助判断资源是否是最新的,引入了ETAG和Last-Modified这两个概念。ETAG是entity tag,可以认为它 是资源的指纹信息,如果资源发生改变,etag必然发生变化。Last-Modified就是资源的修改时间,非常好理 解。
所以如果etag或者last-modified发生变化,可以认为资源过期了。
通常情况下,如果服务端支持缓存,会在响应头部中包含etag或者last-modified头部(或者两者都有)。
而UA在确定缓存过期,或者不能确定缓存是否过期的情况下,可以使用if-none-match:{etag}或者 if-modified-since:{last-modified}来发起条件请求
4.2 明确缓存
服务端明确指定了expires或者Cache-Control的max-age(max-age优先级高于expires),通常这个响应会有 etag或者last-modified头部。
-
UA要求强制刷新(比较少),忽略缓存。
-
根据expires或max-age判断没有过期,直接从缓存给出响应,不需要网络交互
-
缓存过期,发起条件请求(带if-modified-since或者if-none-match头部)向服务器验证,这个时候服务 器通过比对etag或者last-modified,如果没有过期,就返回304 not-modified,UA还是从本地缓存取响应; 服务端如果判定缓存过期,就返回一个200 OK的响应,UA更新本地缓存。
-
服务端经常通过设置expires=-1或者max-age=0来强制缓存进行服务器验证。
4.3 非明确缓存
对于没有明确指定expires或者Cache-Control的max-age的响应,UA无法判断缓存是否过期,这个时候就发起 条件请求,走验证流程。可以认为类似明确缓存里面的缓存过期。
对于Cache-Control里面包含must-revalidate指令的响应,也认为是非明确缓存,必须走验证流程。
4.4 不缓存
服务端可以明确指示UA不要缓存响应(比如一些实时变化的资源),常见的做法是设置Cache-Control的 no-cache。
4.5 实例
GET / HTTP/1.1
Host: www.w3.org
Connection: keep-alive
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1
Upgrade-Insecure-Requests: 1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
If-None-Match: "8f77-55f362f2e7600;89-3f26bd17a2f00-gzip"
If-Modified-Since: Thu, 30 Nov 2017 17:00:08 GMT
HTTP/1.1 200 OK
Date: Thu, 07 Dec 2017 02:00:09 GMT
Content-Location: Home.html
Vary: negotiate,accept,Accept-Encoding
Last-Modified: Wed, 06 Dec 2017 11:00:11 GMT
ETag: "8a9e-55fa9daf2a4c0;89-3f26bd17a2f00-gzip"
Accept-Ranges: bytes
Content-Encoding: gzip
Cache-Control: max-age=600
Expires: Thu, 07 Dec 2017 02:10:09 GMT
Content-Length: 9135
Content-Type: text/html; charset=utf-8
...
GET /2008/site/images/logo-w3c-mobile-lg HTTP/1.1
Host: www.w3.org
Connection: keep-alive
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1
Accept: image/webp,image/apng,image/*,*/*;q=0.8
Referer: https://www.w3.org/
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
If-None-Match: "11a9-485114b0e28c0;53607e2410c9f"
If-Modified-Since: Sun, 25 Apr 2010 15:27:07 GMT
HTTP/1.1 304 Not Modified
Date: Wed, 06 Dec 2017 13:39:59 GMT
Content-Location: logo-w3c-mobile-lg.png
Vary: negotiate,accept,upgrade-insecure-requests
Last-Modified: Sun, 25 Apr 2010 15:27:07 GMT
ETag: "11a9-485114b0e28c0;53607e2410c9f"
Cache-Control: max-age=2592000
Expires: Fri, 05 Jan 2018 13:39:59 GMT
Content-Type: image/png; qs=0.7
5. cookie
前面我们提到过,http协议是无状态的。但是很多时候,后端需要在不同请求之间维护回话 信息,又需要有状态的信息。
常见的场景,比如登录页登录以后,访问其它页面,需要将登录信息 携带过去。这时候一种解决的办法是通过url的query传递登录信息(登陆凭证),但是这种方法需 要将信息在每个页面之间传来传去。另外一种方法就是通过set-cookie存到客户端,则客户端后面 在向服务器发送请求的时候,将回话信息携带给服务端。
另外一个场景就是登陆界面下面的“下次不用登陆“选项,通过cookie来保存登陆凭证,实现一段时 间的免登陆。
所以cookie的实际内容可以看做服务端寄存在客户端的信息,实际内容对客户端透明。
下面是访问http://www.hao123.com的过程,被服务器重定向到https://www.hao123.com,302响应 同时使用set-cookie向客户端寄存信息,客户端在下一个请求https://www.hao123.com中,将寄 存信息带给服务端。
GET / HTTP/1.1
Host: www.hao123.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (iPad; CPU OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
HTTP/1.1 302 Found
Connection: keep-alive
Content-Type: text/html;charset=UTF-8
Date: Thu, 07 Dec 2017 07:07:42 GMT
Location: https://www.hao123.com/
Set-Cookie: hz=0; path=/; domain=www.hao123.com
Set-Cookie: BAIDUID=BDB93253A03B5F8826EAB44C1C8F4E2C:FG=1; expires=Fri, 07-Dec-18 07:07:42 GMT; max-age=31536000; path=/; domain=.hao123.com; version=1
Content-Length: 0
GET / HTTP/1.1
Host: www.hao123.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (iPad; CPU OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1
Upgrade-Insecure-Requests: 1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: hz=0; BAIDUID=BDB93253A03B5F8826EAB44C1C8F4E2C:FG=1
HTTP/1.1 200 OK
Connection: keep-alive
Content-Type: text/html;charset=UTF-8
Date: Thu, 07 Dec 2017 07:07:43 GMT
Set-Cookie: ft=1; expires=Thu, 07-Dec-2017 15:59:59 GMT
Set-Cookie: v_pg=s_51
Set-Cookie: __bsi=10449838630856047604_00_39_N_N_225_0303_c02f_Y; max-age=3600; domain=www.hao123.com; path=/
在app的hybrid开发里面,经常需要在native和web之间传递同步cookie,保证服务端的回话。
因为cookie里面经常携带敏感信息,所以非常容易造成隐私的泄露。
RFC6265里面,cookie是有域和path的概念的,限制了cookie的访问权限。但是在实际 网络环境中,仍然有手段来突破或者绕过这种限制,导致隐私泄露。
6. https
因为http是明文传输的,所以http非常容易被劫持、监听、篡改和攻击。最常见的例子就是运营商 插入广告。
很多http的api通过api验签来提高攻击成本。
尽管如此,还是非常脆弱。这个时候,理所当然地想到对http通讯进行加密。
6.1 对称加密和非对称加密
所谓对称加密就是加密和解密使用同一个秘钥,一般用于1对1通讯。
非对称加密是加密和解密使用不同不同的秘钥,秘钥成对出现,一般分为公钥和私钥,公钥加密的信息 只能私钥解开,私钥加密的信息只能公钥解开。非对称加密经常用于1对N通讯。
6.2 https简单原理
如果服务端和客户端各自保存私钥,通讯过程就可以使用对称加密,非常安全。
问题是这个私钥的传递过程,可能会被截取,而且客户端也可能向假冒的服务端发送了私钥。所以引入了非 对称加密来校验服务器身份以及传递对称的秘钥。
服务端首先生成一对公钥和秘钥,然后向权威机构申请证书,证书中包含公钥信息。服务器保存私钥。
1) 客户端向服务端say hello
2) 服务端向客户端say hello,并告诉服务端自己的证书。
3) 客户端收到证书后,先校验证书,校验通过后,发送一个随机串要求服务端自证清白。
4)服务端加密这个随机串,返回给客户端。
5)客户端解密这个服务端加过密的随机串,再和自己发送的随机串比对,匹配则服务端清白。 然后客户端发送加密算法和对称加密算法的秘钥给服务端。非对称加密
6)开始对称加密通信
1到5步是SSL/TLS握手的过程。
有兴趣的可以看数字证书原理,公钥私钥加密原理 ,讲的通俗易懂。
6.3 https对性能的损耗
https对性能的损耗主要包括两个,一个是握手的成本,一个是数据的加解密。
握手的成本带来的问题是延迟,网络上有人做过实验,https的连接建立过程小时时间大概是http连接建立过程 的四倍。而且非对称加密比较消耗服务器CPU。
数据加解密因为是对称加解密,对服务器CPU损耗很小,但是会降低数据有效载荷(padding是无效载荷),导致 有带宽上的成本。
后来为了减少TLS握手的成本,引入了TLS心跳,通过发送心跳的请求和应答,对TLS Session进行保活,重用session。
参考
